

2021年3月24日
AI研究4年目社員:AI国際学会での発表を通じて
こんにちは、トヨタ自動車(以下、トヨタ)未来創生センターの篠田です。トヨタ入社後に初めて機械学習や人工知能(以下、AI)研究に触れたボクですが、未来創生センターの研究体制や周りの研究者に助けられ、AIのトップ国際学会『IJCAI』で2019年、2020年と2年連続で成果を発表することができました。今回は2021年1月に開催されたIJCAI2020の所感と発表論文の概要、そして未来創生センターの取り組みについてご紹介したいと思います。
IJCAI2020について
IJCAI(International Joint Conference on Artificial Intelligence)はAI分野のトップ国際会議の一つであり、機械学習、自然言語処理、AI倫理など幅広いテーマを扱っています。近年のAI研究の盛り上がりを受けてIJCAIにおいても投稿数が急激に伸びていますが、それに比べて採択数は非常に少なく、結果としてここ数年は採択率(論文発表できる割合)が20%を切る厳しい状況が続いています(図1)。また最近の研究のトレンドとしては性能向上だけでなく、結果の解釈性や公平性など人間の感性に寄り添う技術が重要性を増してきています。
IJCAI2020は本来2020年7月に横浜で開催される予定でしたが、コロナ禍の影響で半年遅れ2021年1月にオンラインで開催されることとなりました。例年は複数の発表が並行して行われるため、興味のある発表を全て聞くのが難しかったのですが、今年は発表動画がいつでも視聴可能であり、オンライン開催のメリットを感じることができました。ただ、現地参加と比較してどうしても議論がぎこちなくなってしまう場面もあり、今後うまい方法を模索していきたいと思いました。
-
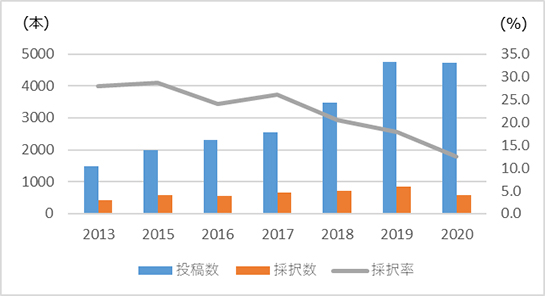
図1:IJCAIにおける投稿数、採択数、採択率の推移(Statistics of acceptance rate for the main AI conferences1より筆者作成)
発表論文の概要
今回発表したのは、Positive-confidence分類2(以下、Pconf分類)と呼ばれる機械学習手法を現実のデータに適用するための研究です(論文はこちら)。Pconf分類は二値分類の技術ですが、従来の教師付き学習よりも実用的な設定として、一方のクラスのデータが全く得られない状況においても学習可能であり、幅広い応用が考えられます(図2)。
-
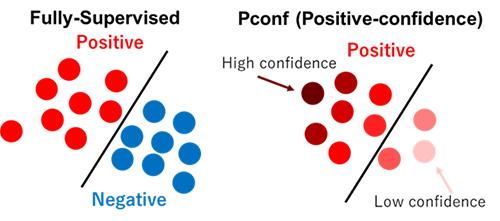
図2:従来の二値分類(左)では両方のクラスのデータが必要なのに対し、Pconf分類(右)では片方のクラスと正信頼度のみを利用
例えば、あるwebサービスでユーザーの属性や利用状況などに基づいて、今後も継続してくれるかを予測したいとします。これは潜在的なユーザー/非ユーザーの分類問題と捉えられますが、手元に非ユーザーのデータはないため通常の学習手法を使うことはできません。このとき、Pconf分類では正信頼度(上の例ではある人がユーザーである確率)を利用することで、非ユーザーの情報なしで学習することが可能になります。正信頼度としては、例えばユーザーごとのロイヤリティスコア(webサービスに対して感じる愛着や満足の度合いを測る指標)を0~1の数値に変換したものを使うことが考えられます。
この手法は正信頼度にある程度のノイズがある場合でも、それほど影響を受けないことが確認されています。しかし、実際には正信頼度の正確な評価は困難であり、評価に偏りがあると性能が低下する可能性があることがわかりました(図3)。webサービスの例では、ロイヤリティスコアは非ユーザーを考慮せずに算出されているため、全体的に過大評価されている可能性があります。
-
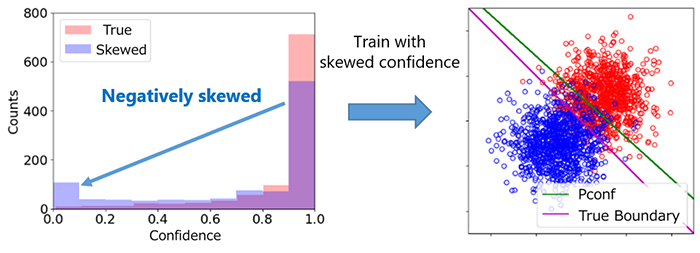
図3:意図的に偏りを生じさせた正信頼度(左)でPconf分類を実施したところ、学習結果も偏ってしまうことを確認(右)
また、この問題の難しさは、学習時点ではユーザーの情報しか持っていないため、正信頼度の偏りの有無や程度を判断できず、うまく補正を行えない点にあります。しかし偏りの補正はPconf分類の実用上、非常に重要な課題であり、今回の研究では「正例の誤分類率」という事前知識を活用することで補正を行う方法を提案しました。詳しい手順は省略しますが、正例の誤分類率は非ユーザーの情報なしで推定することができるため、その推定誤差を最小化するように補正を行うというのが提案法の基本的なアイデアです。正例の誤分類率としては、例えば1年間に離脱したユーザーの割合を使うことができ、集計データから容易に求められる点でも実用的な手法になっています。
様々な条件での性能評価の結果、提案法は畳み込みニューラルネットといった複雑なモデルや、正信頼度が人間の主観的な評価で与えられている現実のデータに対しても有効であることが確かめられました。
未来創生センターにおける機械学習研究
従来の機械学習に必要なデータは実際には収集不可能であったり、非常に高コストであったりするため、最新の機械学習技術を社会実装していくには現場の事情にも適応させていく必要があります。未来創生センターではそうした研究の重要性にいち早く注目して2013年より東京大学の杉山将教授と共同研究を推進しており、今回の論文も含めこれまでに以下のような成果を発表してきました。
- Binary Classification Only from Unlabeled Data by Iterative Unlabeled-unlabeled Classification (ICASSP2019)3
- Multi Task Learning with Positive and Unlabeled Data and its Application to Mental State Prediction (ICASSP2018)4
このように未来創生センターでは、将来のリアルなひと、まち、社会を支える基盤技術としての機械学習研究に積極的に取り組んでおり、世界トップレベルの技術に触れることのできる環境が整っています。私自身、大学、大学院での専門は機械学習ではありませんでしたが、入社してから共同研究などを通じてスキルを積むことで、国際会議で研究発表できるまでに専門性を高めることができました。今後もよりよい社会づくりに貢献できるよう、さらなるレベルアップを目指していきたいと思います。
未来のための幅広く研究を
今回はIJCAI2020発表論文を中心に機械学習研究についてご紹介しましたが、未来創生センターでは他にもロボティクス、革新的インフラ、バイオなどに関する魅力的な研究に取り組んでいます。ぜひサイト内の他の記事も読んでみてください。こうした幅広いバックグラウンドを持つ研究者、技術者が互いに刺激を与えながら、Well-beingな社会実現に向けて挑戦できる環境が未来創生センターの強みの一つです。今後も発信を続けていきますので、お楽しみに!
未来創生センターの求人情報はこちらをご覧ください。

篠田 和彦
経済学(学士)、システム工学(修士)、2017年入社。これまで主に機械学習による人の状態推定に関する研究に携わる。最近では、計量経済学や計算論的神経科学に興味を持つ。頭の中を整理するための散歩・ランニングが日課。休日は映画を観たり、音楽を聴いたりしてリラックスしている。
左写真)IJCAI2019の合間に世界一高いバンジー飛んできました!@マカオタワー
参考文献
- 1
- https://github.com/lixin4ever/Conference-Acceptance-Rate
- 2
- Takashi Ishida, Gang Niu, and Masashi Sugiyama. 2018. Binary classification from positive-confidence data. In Proceedings of the 32nd International Conference on Neural Information Processing Systems.
- 3
- Hirotaka Kaji and Masashi Sugiyama. 2019. Binary Classification Only from Unlabeled Data by Iterative Unlabeled-unlabeled Classification. In 2019 IEEE International Conference on Acoustics, Speech and Signal Processing.
- 4
- Hirotaka Kaji, Hayato Yamaguchi, and Masashi Sugiyama. 2018. Multi task learning with positive and unlabeled data and its application to mental state prediction. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing.